
admin

2153
Gần đây, việc nhà mạng phát triển thuật toán nhận diện khuôn mặt ngày càng thu hút được nhiều sự quan tâm của cộng đồng doanh nghiệp trong nước và quốc tế. Tuy nhiên, các phép đo chuẩn độ chính xác cho các hệ thống như vậy không phải là nhỏ và có nhiều sắc thái. Chúng tôi thường xuyên nhận được các yêu cầu thử nghiệm đối với công nghệ nhận dạng của chúng tôi và các chương trình thử nghiệm dựa trên công nghệ này và chúng tôi nhận thấy các vấn đề phổ biến với thuật ngữ, thử nghiệm các phương pháp tiếp cận theo thuật toán liên quan đến các vấn đề kinh doanh. Kết quả là, công cụ sai có thể được chọn để giải quyết một vấn đề dẫn đến tổn thất tài chính hoặc không có lợi nhuận. Chúng tôi quyết định xuất bản bài viết này để giúp mọi người làm quen với các thuật ngữ kỹ thuật và dữ liệu thô về công nghệ nhận diện khuôn mặt và để so sánh dễ dàng hơn. Chúng tôi muốn trao đổi với bạn về các khái niệm cơ bản của lĩnh vực này bằng ngôn ngữ đơn giản và chỉ ra cách hoạt động của hệ thống nhận diện khuôn mặt dựa trên thuật toán. Hy vọng rằng điều này sẽ mang lại tiếng nói cho các nhà công nghệ và doanh nhân để hiểu rõ hơn về các kịch bản sử dụng nhận diện khuôn mặt trong thế giới thực, đưa ra quyết định sáng suốt và xác thực dữ liệu.
Tìm Hiểu Thêm: Máy Chấm Công Khuôn Mặt Chính Hãng Tại Hà Nội
nhận diện khuôn mặt thường được coi là tập hợp các tác vụ khác nhau, chẳng hạn như phát hiện khuôn mặt trong ảnh hoặc trong luồng video, xác định giới tính và tuổi, tìm đúng người trong nhiều hình ảnh có khuôn mặt hoặc xác minh xem hai hình ảnh có thuộc cùng một người hay không. Trong bài báo này, chúng tôi sẽ tập trung vào hai nhiệm vụ cuối cùng và gọi chúng là công nhận và xác minh, tương ứng. Để giải quyết những vấn đề này, các bộ mô tả khuôn mặt đặc biệt hoặc các vectơ biểu tượng cần thiết để nhận diện khuôn mặt sẽ được trích xuất từ hình ảnh. Trong trường hợp này, nhiệm vụ nhận dạng được giảm xuống để tìm vectơ đặc trưng gần nhất và việc xác minh có thể được thực hiện bằng cách sử dụng một ngưỡng đơn giản về khoảng cách giữa các vectơ. Bằng cách kết hợp hai hành động này, hệ thống có thể xác định một người từ hình ảnh khuôn mặt nhất định hoặc xác định xem người đó có trong hình ảnh đang được phân tích hay không. Quá trình này được gọi là nhận dạng tập hợp mở, xem Hình 1.

Khoảng cách của không gian vectơ có thể được sử dụng để đánh giá định lượng độ giống nhau của khuôn mặt và khoảng cách không gian của vectơ đặc trưng khuôn mặt có thể được sử dụng. Khoảng cách euclide hoặc cosine thường được chọn, nhưng các phương pháp khác phức tạp hơn được sử dụng để xác định. Khả năng khoảng cách cụ thể thường được cung cấp như một phần của các sản phẩm nhận diện khuôn mặt. Việc xác định và xác minh trả về các kết quả khác nhau, vì vậy cần sử dụng các số liệu khác nhau để đánh giá chất lượng của chúng. Chúng tôi trình bày chi tiết các chỉ số chất lượng trong các phần sau. Ngoài việc chọn một số liệu thích hợp, việc đánh giá độ chính xác của thuật toán yêu cầu một tập hợp các hình ảnh được gắn nhãn (tập dữ liệu).
Hầu hết tất cả các phần mềm sinh trắc học trên khuôn mặt hiện đại đều được xây dựng trên máy học. Các thuật toán nhận diện khuôn mặt được đào tạo trên các tập dữ liệu lớn (dataset) với các hình ảnh được gắn nhãn. Cả chất lượng và bản chất của các bộ dữ liệu này đều có tác động đáng kể đến độ chính xác. Dữ liệu ban đầu càng tốt thì thuật toán có thể giải quyết một nhiệm vụ nhất định càng tốt.
Một cách tự nhiên để kiểm tra độ chính xác của hệ thống nhận diện khuôn mặt là đo độ chính xác của nhận dạng trên một tập dữ liệu kiểm tra riêng biệt. Lựa chọn tập dữ liệu phù hợp là rất quan trọng. Tốt nhất, các tổ chức nên có được bộ dữ liệu của riêng họ càng gần với hình ảnh mà hệ thống sẽ có trong quá trình hoạt động càng tốt. Cần chú ý đến máy ảnh, điều kiện chụp, tuổi, giới tính và quốc tịch của những người sẽ được đưa vào bộ dữ liệu thử nghiệm. Tập dữ liệu thử nghiệm càng giống với dữ liệu thực thì kết quả thử nghiệm càng đáng tin cậy và độ chính xác càng cao. Do đó, thường mất rất nhiều thời gian và tiền bạc để thu thập và gắn nhãn các tập dữ liệu của bạn. Nếu điều này không thể thực hiện được vì lý do nào đó, bạn có thể sử dụng các bộ dữ liệu công khai như LFW và MegaFace. LFW chỉ chứa 6000 cặp hình ảnh khuôn mặt và không phù hợp với nhiều trường hợp thực tế: đặc biệt, với bộ dữ liệu này, không thể đo ở mức sai số thấp mà chúng tôi sẽ trình bày dưới đây. Bộ dữ liệu MegaFace chứa nhiều hình ảnh hơn và phù hợp để thử nghiệm các thuật toán nhận diện khuôn mặt trên quy mô lớn. Tuy nhiên, cả bộ hình ảnh đào tạo và kiểm tra cho MegaFace đều được cung cấp công khai, vì vậy cần cẩn thận khi kiểm tra chúng.
Một tùy chọn khác là sử dụng kết quả của bài kiểm tra của bên thứ ba. Các bài kiểm tra như vậy được thực hiện bởi các chuyên gia có trình độ trên tập dữ liệu lớn về con người và kết quả có thể được tin cậy. Một ví dụ là thử nghiệm nhà cung cấp nhận diện khuôn mặt NIST đang diễn ra. Đây là thử nghiệm do Viện Tiêu chuẩn và Công nghệ Quốc gia (NIST) thực hiện. Bởi Bộ Thương mại Hoa Kỳ. Nhược điểm của cách tiếp cận này là tập dữ liệu cho tổ chức thử nghiệm có thể rất khác với bối cảnh quan tâm.
Như chúng tôi đã nói, học máy là trung tâm của phần mềm nhận diện khuôn mặt hiện đại. Một trong những hiện tượng học máy phổ biến nhất là đào tạo lại. Có thể thấy, thuật toán hoạt động tốt trên các khuôn mặt được sử dụng trong quá trình đào tạo, nhưng lại hoạt động kém hơn nhiều trên dữ liệu mới.
Hãy xem một ví dụ cụ thể: Giả sử một khách hàng muốn lắp đặt hệ thống cửa đến cửa tốt nhất bằng cách sử dụng nhận diện khuôn mặt. Để làm được điều này, anh đã thu thập một bộ ảnh của những người được phép ra vào và đào tạo một thuật toán để phân biệt khuôn mặt của họ với khuôn mặt của những người khác. Trong giai đoạn thử nghiệm và kiểm tra, hệ thống cho kết quả tốt và được đưa vào sử dụng. Sau một thời gian, danh sách những người được phép ra vào ngày một nhiều lên, hệ thống nhận diện khuôn mặt sẽ hoạt động như thế nào bây giờ? - Từ chối người mới đến và không cho nhập cảnh. Thuật toán đã được thử nghiệm trên các khuôn mặt giống như nó đã được đào tạo và không ai đo độ chính xác của các bức ảnh mới. Tất nhiên, đây là một ví dụ phóng đại, nhưng nó giúp chúng ta hiểu được vấn đề.
Trong một số trường hợp, việc đào tạo lại sẽ không đáng chú ý. Giả sử một thuật toán nhận diện khuôn mặt được đào tạo trên hình ảnh của những người có sắc tộc thống trị. Nếu một công ty đa văn hóa (tức là có nhiều chủng tộc khác nhau) sử dụng thuật toán phân tích khuôn mặt này, độ chính xác của nó có thể giảm xuống. Tối ưu hóa quá mức độ chính xác của một thuật toán do thử nghiệm kém là một sai lầm rất phổ biến. Một thuật toán luôn cần được thử nghiệm trên dữ liệu mới, dữ liệu mà nó phải xử lý trong thực tế, chứ không phải dữ liệu mà nó đã được đào tạo.
Với tất cả những gì đã nói, chúng tôi có thể liệt kê các khuyến nghị: không sử dụng ảnh của các khuôn mặt mà thuật toán đã đào tạo trong quá trình thử nghiệm, hãy sử dụng một tập dữ liệu đóng đặc biệt để thử nghiệm. Nếu điều này không thể thực hiện được, hãy sử dụng tập dữ liệu công khai và đảm bảo rằng nhà cung cấp không sử dụng nó trong quá trình đào tạo và / hoặc điều chỉnh thuật toán. Nghiên cứu tập dữ liệu trước khi thử nghiệm và suy nghĩ về mức độ gần gũi của nó với dữ liệu mà thuật toán sẽ xử lý trong khi hệ thống đang chạy.
Sau khi chọn tập dữ liệu, bạn nên quyết định số liệu nào sẽ được sử dụng để đánh giá kết quả. Trong trường hợp chung, số liệu là một hàm lấy hiệu suất của thuật toán làm đầu vào (nhận dạng hoặc xác thực) và trả về đầu ra một số tương ứng với hiệu suất của thuật toán nói trên, tức là một tập dữ liệu cụ thể. So sánh định lượng giữa các thuật toán hoặc nhà cung cấp khác nhau sử dụng số có thể trình bày kết quả nhận dạng một cách chính xác và hỗ trợ trong việc ra quyết định. Trong phần này, chúng ta sẽ xem xét các số liệu được sử dụng phổ biến nhất trong nhận diện khuôn mặt và thảo luận về ý nghĩa của chúng từ góc độ kinh doanh.
Xác minh khuôn mặt có thể được xem như một quá trình quyết định nhị phân: «Có» (hai bức ảnh thuộc về cùng một người), «Không» (nhiều bức ảnh hiển thị những người khác nhau). Trước khi hiểu các chỉ số xác thực, sẽ rất hữu ích nếu hiểu cách chúng tôi phân loại lỗi trong các nhiệm vụ như vậy. Lưu ý rằng thuật toán có 2 câu trả lời có thể có và 2 tùy chọn cho cách mọi thứ thực sự như thế nào, vì vậy có 4 kết quả có thể xảy ra:

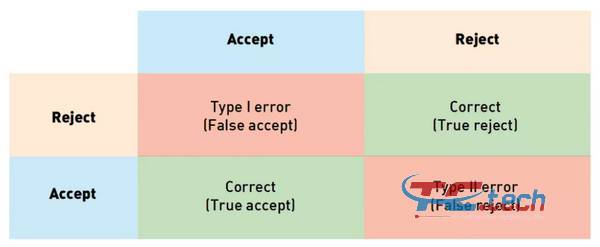
Trong bảng trên, các cột tương ứng với các quyết định của thuật toán (màu xanh lam - chấp nhận, màu vàng - từ chối) và các hàng tương ứng với các giá trị thực tế (được mã hóa bằng cùng một màu). Câu trả lời đúng của thuật toán được đánh dấu bằng nền xanh và câu trả lời sai được đánh dấu bằng nền đỏ. Trong số này, hai tương ứng với các câu trả lời đúng của thuật toán, và hai tương ứng với các lỗi của loại thứ nhất và thứ hai. Loại lỗi đầu tiên được gọi là "sai số chấp nhận", "kết quả xác thực sai" hoặc "đối sánh sai" và loại lỗi thứ hai được gọi là "từ chối sai", "phủ định sai" hoặc "không khớp sai" (từ chối sai). Hình ảnh trong tập dữ liệu Lấy số lượng các loại lỗi khác nhau giữa các cặp và chia chúng cho logarit, chúng tôi nhận được tỷ lệ chấp nhận sai (FAR) và tỷ lệ từ chối sai, FRR). Trong ngữ cảnh của hệ thống kiểm soát truy cập, "dương tính giả" tương ứng với việc cấp quyền truy cập cho người không được cấp quyền truy cập, trong khi "dương tính giả" có nghĩa là hệ thống từ chối quyền truy cập. Nhập hoặc thoát không đúng người được phép vào. Từ góc độ kinh doanh, những khiếm khuyết này có chi phí khác nhau và cần được xem xét riêng lẻ. Trong ví dụ về kiểm soát truy cập, "dương tính giả" sẽ khiến nhân viên bảo vệ kiểm tra lại thẻ ra vào của nhân viên. Việc cho phép những người vi phạm tiềm ẩn ra vào (dương tính giả) có thể dẫn đến hậu quả tồi tệ hơn. Vì các loại lỗi khác nhau có liên quan đến các rủi ro khác nhau, các nhà sản xuất phần mềm nhận diện khuôn mặt thường cho phép điều chỉnh các thuật toán để giảm thiểu một trong số các loại lỗi. Để làm điều này, thuật toán trả về không phải là giá trị nhị phân mà là một số thực phản ánh sự tự tin của thuật toán đối với quyết định của nó. Trong trường hợp này, người dùng có thể độc lập chọn ngưỡng và sửa mức lỗi ở các giá trị nhất định. Ví dụ: hãy xem xét một tập dữ liệu đồ chơi gồm ba hình ảnh. Giả sử hình ảnh 1 và 2 thuộc về cùng một người, và hình ảnh 3 thuộc về người khác. Giả sử chương trình đánh giá độ tin cậy của nó đối với từng cặp trong số ba cặp như sau:
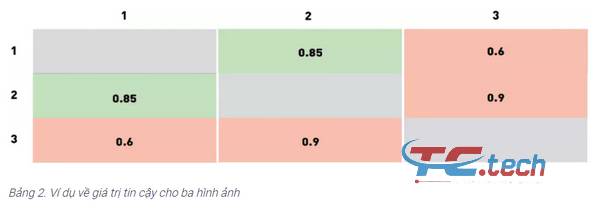
Chúng tôi đã cố tình chọn các giá trị này để không có ngưỡng phân loại chính xác cả ba cặp. Cụ thể, bất kỳ ngưỡng nào dưới 0,6 sẽ dẫn đến hai cặp chấp nhận sai (cặp 2-3 và 1-3). Tất nhiên, kết quả này có thể được cải thiện.
Chọn ngưỡng giữa 0,6 và 0,85 sẽ dẫn đến việc cặp 1-3 bị loại, mặt 1-2 vẫn được chấp nhận và cặp 2-3 bị chấp nhận sai. Nếu nâng ngưỡng lên 0,85−0,9, 1−2 cặp sẽ bị từ chối sai. Ngưỡng trên 0,9 sẽ dẫn đến hai cặp từ chối đúng (cặp 1-3 và 2-3) và một từ chối sai (1-2). Vì vậy, có vẻ như các lựa chọn tốt nhất là ngưỡng trong phạm vi 0,6-0,85 (một cặp được chấp nhận sai 2-3) và ngưỡng trên 0,9 (dẫn đến bị từ chối sai 1-2). Cuối cùng, việc chọn giá trị nào phụ thuộc vào chi phí của các loại lỗi khác nhau. Trong ví dụ này, các ngưỡng rất khác nhau, chủ yếu là do tập dữ liệu rất nhỏ và cách chúng tôi chọn các giá trị tin cậy cho thuật toán. Đối với các tập dữ liệu lớn được sử dụng cho các tác vụ trong thế giới thực, chúng tôi sẽ thu được các ngưỡng chính xác hơn. Thông thường, các nhà cung cấp phần mềm nhận diện khuôn mặt đưa ra các ngưỡng mặc định cho các FAR khác nhau, các ngưỡng này được tính toán tương tự trên tập dữ liệu của chính nhà cung cấp.
Cũng có thể dễ dàng nhận thấy rằng khi FAR giảm, ngày càng nhiều cặp hình ảnh dương tính được yêu cầu để tính toán chính xác điểm cắt. Do đó, đối với FAR = 0,001, cần ít nhất 1000 cặp và đối với FAR = 10−6, cần 1 triệu cặp. Việc thu thập và gắn nhãn các bộ dữ liệu như vậy không dễ dàng, vì vậy khách hàng quan tâm đến giá trị FAR thấp nên chú ý đến các điểm chuẩn có sẵn công khai như Kiểm tra nhà cung cấp nhận diện khuôn mặt NIST hoặc MegaFace. Sau đó, điều này cần được xử lý một cách thận trọng, vì mọi người đều có quyền truy cập vào cả các mẫu thử nghiệm và đào tạo, điều này có thể dẫn đến các đánh giá quá lạc quan về độ chính xác (xem phần "Đào tạo lại").
Các loại lỗi khác nhau tùy theo chi phí và khách hàng có cách chuyển đổi số dư chi phí thành các lỗi nhất định. Đối với điều này, cần phải xem xét một loạt các ngưỡng. Để dễ dàng hình dung độ chính xác của thuật toán ở các giá trị FAR khác nhau, đồ thị đường cong ROC được sử dụng.
Hãy xem cách xây dựng và phân tích đường cong ROC. Độ tin cậy của thuật toán (từ đó ngưỡng được suy ra) nhận một khoảng giá trị cố định. Nói cách khác, các giá trị này được giới hạn lên và xuống. Giả sử phạm vi này là 0 đến 1. Giờ đây, chúng tôi có thể đo lường số lỗi bằng cách thay đổi ngưỡng từ 0 thành 1 theo từng bước nhỏ. Vì vậy, đối với mỗi ngưỡng, chúng tôi nhận được các giá trị FAR và TAR (Tỷ lệ chấp nhận thực). Tiếp theo, chúng ta sẽ vẽ từng điểm sao cho FAR tương ứng với trục hoành và TAR với trục tung.
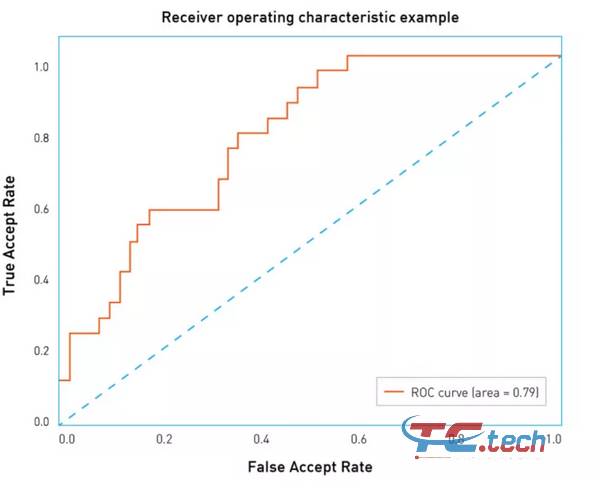
Dễ dàng nhận thấy điểm đầu tiên có tọa độ là 1,1. Sử dụng ngưỡng 0, chúng tôi chấp nhận tất cả các cặp khuôn mặt và không từ chối. Tương tự, điểm cuối cùng sẽ là 0.0: ở ngưỡng 1, chúng tôi không chấp nhận các cặp mặt và từ chối tất cả các cặp mặt. Ở các điểm khác, đường cong thường lồi. Bạn cũng có thể nhận thấy rằng đường cong xấu nhất nằm gần đúng trên đường chéo của biểu đồ và tương ứng với một dự đoán ngẫu nhiên về kết quả. Nếu không, đường cong tốt nhất có thể tạo thành một tam giác với các đỉnh (0,0) (0,1) và (1,1). Nhưng trên một tập dữ liệu có kích thước hợp lý, điều này khó xảy ra.
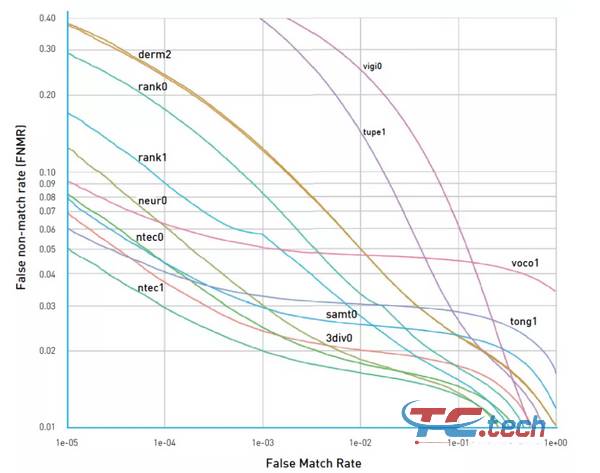
Các đường cong ROC với các số liệu / sai số khác nhau có thể được xây dựng tương tự trên các trục. Ví dụ, hãy xem xét Hình 4. Trên biểu đồ, rõ ràng là các nhà tổ chức của NIST FRVT đã vẽ biểu đồ FRR (trên - tỷ lệ không khớp sai) trên trục Y và FAR (trên - tỷ lệ không khớp sai) trên trục X. Trong trường hợp cụ thể này, kết quả tốt nhất thu được với một đường cong nằm bên dưới và dịch chuyển sang trái, tương ứng với FRR và FAR thấp. Do đó, cần quan tâm đến các giá trị nào được vẽ dọc theo trục.
Biểu đồ như vậy giúp dễ dàng đánh giá độ chính xác của một thuật toán cho một FAR nhất định: chỉ cần tìm điểm trên đường cong mà tọa độ X bằng FAR mong muốn và giá trị TAR tương ứng là đủ. "Chất lượng" của đường cong ROC cũng có thể được ước tính bằng một con số, mà chúng ta cần tính diện tích bên dưới nó. Trong trường hợp này, giá trị tốt nhất có thể là 1, trong khi giá trị 0,5 tương ứng với một dự đoán ngẫu nhiên. Con số này được gọi là ROC AUC (diện tích dưới đường cong). Tuy nhiên, cần lưu ý rằng ROC AUC mặc nhiên giả định rằng lỗi Loại I và Loại II là giống nhau, điều này không phải lúc nào cũng đúng. Nếu chi phí sai khác, bạn nên chú ý đến hình dạng của đường cong và khu vực mà FAR đáp ứng nhu cầu kinh doanh.
Nhiệm vụ nhận diện khuôn mặt phổ biến thứ hai là xác định, nhận dạng hoặc tìm khuôn mặt mong muốn trong một bộ ảnh. Kết quả tìm kiếm khuôn mặt được sắp xếp theo độ tin cậy của thuật toán, với kết quả phù hợp nhất ở đầu danh sách. Theo việc liệu người đang được tìm kiếm có tồn tại trong cơ sở dữ liệu tìm kiếm người hay không, danh tính được chia thành hai loại phụ: danh tính nhóm kín (người được tìm kiếm tồn tại trong cơ sở dữ liệu) và nhận dạng nhóm mở (người được tìm kiếm có thể không có trong cơ sở dữ liệu mặt) giữa).
Độ chính xác là một chỉ số và thước đo đáng tin cậy và được hiểu rõ để xác định các nhóm kín. Về cơ bản, độ chính xác đo lường số lần một người được mong đợi xuất hiện trong kết quả tìm kiếm khuôn mặt.
Nó hoạt động như thế nào trong thực tế? Chúng ta sẽ cùng nhau tìm hiểu. Hãy bắt đầu bằng cách xây dựng các yêu cầu kinh doanh. Giả sử chúng ta có một trang web có thể lưu trữ mười kết quả tìm kiếm. Chúng tôi cần đo lường số lần người tìm kiếm nhận được mười phản hồi hàng đầu của thuật toán. Con số này được gọi là độ chính xác Top-N (trong trường hợp cụ thể này, N bằng 10).
Đối với mỗi bài kiểm tra, chúng tôi xác định hình ảnh của người mà chúng tôi đang tìm kiếm và xác định nhóm khuôn mặt chúng tôi đang tìm kiếm, để bộ đó chứa ít nhất nhiều hình ảnh hơn về người này. Chúng tôi xem xét mười kết quả hàng đầu của thuật toán tìm kiếm và kiểm tra xem người mà chúng tôi đang tìm kiếm có nằm trong số đó hay không. Để có được độ chính xác, hãy cộng tất cả các thử nghiệm của người tìm kiếm trong kết quả tìm kiếm và chia cho tổng số thử nghiệm.

Nhận dạng tập hợp mở bao gồm việc tìm những người giống nhất với hình ảnh được tìm thấy và xác định xem bất kỳ ai trong số họ có phải là người tìm trái tim hay không dựa trên độ tin cậy của thuật toán. Danh tính nhóm mở có thể được coi là sự kết hợp của xác minh và xác minh nhóm kín, vì vậy trong tác vụ này, tất cả các chỉ số có thể được áp dụng như trong tác vụ xác minh. Cũng dễ dàng nhận thấy rằng danh tính tập hợp mở có thể được giảm xuống để so sánh theo cặp giữa hình ảnh mong muốn và tất cả các hình ảnh trong thư viện. Trên thực tế, điều này không được sử dụng vì lý do tốc độ tính toán. Phần mềm nhận diện khuôn mặt thường đi kèm với các thuật toán tìm kiếm nhanh có thể tìm thấy khuôn mặt giống nhau trong số hàng triệu khuôn mặt chỉ trong mili giây. Việc so sánh theo cặp sẽ mất nhiều thời gian hơn.
Để minh họa, hãy xem một vài ví dụ về cách đo lường chất lượng của các thuật toán nhận diện khuôn mặt để so sánh trong cuộc sống thực.
Giả sử một nhà bán lẻ hạng trung muốn cải thiện chương trình khách hàng thân thiết của mình hoặc giảm hành vi trộm cắp. Từ góc độ sinh trắc học khuôn mặt, hai mục tiêu là giống nhau. Mục tiêu chính của dự án là xác định khách hàng trung thành hoặc những kẻ xâm nhập từ hình ảnh camera càng nhanh càng tốt và chuyển thông tin này cho người bán hoặc nhân viên an ninh.
Tiếp cận 100 khách hàng với chương trình khách hàng thân thiết. Tác vụ này có thể được coi là một ví dụ về danh tính được thiết lập mở. Sau khi đánh giá các chi phí, bộ phận tiếp thị kết luận rằng việc nhầm lẫn du khách với những người thông thường hàng ngày là một mức độ sai sót có thể chấp nhận được. Nếu 1000 khách hàng ghé thăm cửa hàng mỗi ngày và mỗi khách hàng phải được so khớp với danh sách 100 khách hàng thường xuyên, FAR yêu cầu sẽ là 1 / (1000 * 100) = 10−5.
Sau khi xác định mức lỗi có thể chấp nhận được, một tập dữ liệu thích hợp nên được chọn để kiểm tra. Một lựa chọn tốt là đặt máy ảnh ở đúng vị trí (nhà cung cấp có thể trợ giúp về thiết bị cụ thể và tư vấn về vị trí đặt). Bằng cách đối sánh, so sánh các giao dịch của chủ thẻ khách hàng thân thiết với hình ảnh camera và thực hiện lọc thủ công, các nhân viên cửa hàng có thể thu thập một tập hợp các cặp khuôn mặt "tích cực". Cũng có ý nghĩa khi thu thập một tập hợp các hình ảnh khách truy cập ngẫu nhiên (một hình ảnh cho mỗi người). Tổng số hình ảnh phải tương ứng với lượng khách đến cửa hàng mỗi ngày. Bằng cách kết hợp hai tập hợp này, bạn sẽ có được một tập dữ liệu gồm các cặp "tích cực" và "tiêu cực".
Khoảng một nghìn cặp "dương tính" là đủ để kiểm tra độ chính xác nhận dạng cần thiết. Bằng cách kết hợp các khách hàng thường xuyên và không thường xuyên khác nhau, có thể thu thập được khoảng 100.000 cặp "âm".
Bước tiếp theo là chạy (hoặc yêu cầu nhà cung cấp chạy) phần mềm và lấy mức độ tin cậy cho từng cặp thuật toán từ tập dữ liệu. Trong quá trình này, người ta có thể vẽ đường cong ROC và xác minh rằng số lượng khách hàng lặp lại chính xác với FAR = 10−5 có đáp ứng được nhu cầu kinh doanh hay không.
Các sân bay hiện đại xử lý hàng chục triệu lượt hành khách mỗi năm và khoảng 300.000 người qua kiểm soát hộ chiếu mỗi ngày. Tự động hóa quy trình này sẽ giúp giảm chi phí đáng kể. Mặt khác, tội phạm không muốn qua kiểm tra hải quan, và các nhà quản lý sân bay muốn giảm thiểu nguy cơ xảy ra những vụ việc như vậy. FAR = 10−7 tương ứng với mười người vi phạm mỗi năm, điều này có vẻ hợp lý trong trường hợp này. Sử dụng giá trị FAR này, với FRR bằng 0,1 (tương ứng với kết quả của NtechLab dựa trên tiêu chuẩn hình ảnh thị thực NIST), chi phí xác thực tài liệu theo cách thủ công có thể giảm đi một phần 10. Tuy nhiên, để ước tính độ chính xác của một mức FAR nhất định, cần phải có hàng chục triệu hình ảnh. Việc thu thập một tập dữ liệu lớn như vậy đòi hỏi rất nhiều tiền và có thể cần thêm sự đồng ý cho việc xử lý dữ liệu cá nhân. Do đó, việc đầu tư vào các hệ thống nêu trên có thể mất nhiều thời gian để thu hồi vốn. Trong trường hợp này, bạn nên tham khảo Bài kiểm tra nhà cung cấp nhận diện khuôn mặt NIST, bao gồm tập dữ liệu có ảnh của người có thị thực. Các nhà quản lý sân bay nên chọn nhà cung cấp dựa trên việc thử nghiệm bộ dữ liệu này và xem xét lưu lượng hành khách.
Cho đến nay, chúng tôi đã xem xét các ví dụ mà khách hàng đặt hàng quan tâm đến FAR thấp, nhưng không phải lúc nào cũng vậy. Hãy tưởng tượng một không gian quảng cáo được trang bị camera trong một trung tâm mua sắm lớn. Trung tâm mua sắm có chương trình khách hàng thân thiết của riêng mình và muốn xác định những người tham gia ghé qua quầy. Ngoài ra, các chiết khấu và ưu đãi hấp dẫn có thể được gửi qua thư (gửi riêng) cho những cá nhân này dựa trên sự quan tâm của họ đối với gian hàng.
Giả sử rằng một hệ thống như vậy sẽ tốn 10 đô la để chạy và có khoảng 1.000 khách ghé thăm quầy mỗi ngày. Tiếp thị ước tính lợi nhuận là $ 0,0105 cho mỗi email được nhắm mục tiêu. Chúng tôi muốn xác định càng nhiều đối tượng chính quy càng tốt mà không làm phiền người khác quá nhiều. Để loại thư này thành công, độ chính xác phải bằng chi phí gian hàng chia cho số lượng khách truy cập và doanh thu kỳ vọng trên mỗi thư. Ví dụ của chúng tôi, độ chính xác là 10 / (1000 * 0,0105) = 95%. Quản trị viên trung tâm thương mại có thể thu thập bộ dữ liệu như được mô tả trong phần "Cửa hàng bán lẻ" và đo lường độ chính xác như được mô tả trong phần "Nhận dạng". Dựa trên kết quả thử nghiệm, có thể xác định xem liệu có thu được lợi ích mong đợi từ việc sử dụng hệ thống nhận diện khuôn mặt hay không.
Trong bài viết này, chúng tôi chủ yếu thảo luận về vấn đề làm việc với hình ảnh, ít đề cập đến việc phát trực tuyến video. Video có thể được coi là một chuỗi các hình ảnh tĩnh, vì vậy các chỉ số, chỉ số và phương pháp kiểm tra độ chính xác của hình ảnh cũng có thể được áp dụng cho video. Cần lưu ý rằng việc xử lý video phát trực tuyến tốn kém hơn nhiều về mặt tính toán và đặt ra các ràng buộc bổ sung đối với tất cả các giai đoạn nhận diện khuôn mặt. Khi làm việc với video, cần có một bài kiểm tra hiệu suất riêng, vì vậy bài viết này sẽ không trình bày chi tiết quá trình đó.
Trong phần này, chúng tôi liệt kê các vấn đề và sai lầm phổ biến khi thử nghiệm phần mềm nhận diện khuôn mặt, đồng thời đưa ra lời khuyên về cách tránh chúng.
Bạn phải luôn cẩn thận khi chọn tập dữ liệu để thử nghiệm các thuật toán nhận diện khuôn mặt. Một trong những thuộc tính quan trọng nhất của tập dữ liệu là kích thước của nó. Kích thước của tập dữ liệu nên được chọn dựa trên nhu cầu kinh doanh và giá trị FAR / TAR. Tập dữ liệu "đồ chơi" (dữ liệu "nháp") bao gồm một số hình ảnh về các khuôn mặt trong văn phòng của bạn giúp bạn "chơi" với một thuật toán, đo lường hiệu suất của nó hoặc kiểm tra nó. Kiểm tra các trường hợp không chuẩn, nhưng bạn không thể đưa ra kết luận về độ chính xác của thuật toán dựa trên đó. Để kiểm tra độ chính xác, nên sử dụng tập dữ liệu có kích thước hợp lý.
Đôi khi, người ta kiểm tra các thuật toán của hệ thống nhận diện khuôn mặt với một ngưỡng cố định (thường là mặc định của nhà sản xuất) và chỉ xem xét một loại lỗi. Điều này không chính xác vì các ngưỡng mặc định khác nhau tùy theo nhà cung cấp hoặc được chọn dựa trên các giá trị FAR hoặc TAR khác nhau. Khi kiểm tra, hãy để ý cả hai loại lỗi.
Các tập dữ liệu khác nhau về kích thước, chất lượng và độ phức tạp nên không thể so sánh kết quả của các thuật toán trên các tập dữ liệu khác nhau. Bạn có thể dễ dàng từ chối giải pháp tốt nhất vì nó được thử nghiệm trên tập dữ liệu phức tạp hơn đối thủ.
Nên thử nghiệm trên nhiều tập dữ liệu. Khi chọn một tập dữ liệu công khai, chúng ta không thể chắc chắn rằng nó sẽ không được sử dụng khi huấn luyện hoặc điều chỉnh thuật toán. Trong trường hợp này, độ chính xác sẽ được đánh giá quá cao. May mắn thay, khả năng điều này xảy ra có thể được giảm bớt bằng cách so sánh kết quả từ các bộ dữ liệu khác nhau.
Trong bài báo này, chúng tôi mô tả các khối xây dựng chính để thử nghiệm các thuật toán nhận diện khuôn mặt: bộ dữ liệu, nhiệm vụ, số liệu liên quan và các tình huống phổ biến.
Xem Thêm:
Tất nhiên, đây không phải là tất cả những gì chúng tôi muốn nói đến khi thử nghiệm và trong nhiều trường hợp đặc biệt, trình tự hoạt động tối ưu có thể khác nhau (nhóm NtechLab sẽ sẵn lòng trợ giúp bạn điều này). Nhưng chúng tôi thực sự hy vọng bài viết này đã giúp bạn lập kế hoạch phù hợp cho các bài kiểm tra của mình, so sánh một số thuật toán nhận diện khuôn mặt, đánh giá ưu và nhược điểm của chúng và giải thích các chỉ số chất lượng từ góc độ kinh doanh để cuối cùng chọn ra hệ thống nhận diện khuôn mặt tốt nhất.
Mọi thông tin chi tiết, Quý khách vui lòng liên hệ trực tiếp với TCtech theo thông tin như sau:

admin
2104
Bất cứ ai đã từng đi máy bay có lẽ đã đi qua cổng dò…

admin
1457
Để giảm nguy cơ gây hại cho cá nhân và tài chính, cổng dò kim…

admin
1793
Một trong những điều quan trọng nhất đối với mỗi người điều hành bãi giữ…

admin
1563
Bạn đang tự hỏi ưu điểm của hệ thống quản lý bãi đậu xe là…



 Máy chấm công
Máy chấm công



